前言 Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案,分析网站的访问情况时我们一般会借助Google/百度/CNZZ等方式嵌入JS做数据统计,但是当网站访问异常或者被攻击时我们需要在后台分析如Nginx的具体日志,而Nginx日志分割/GoAccess/Awstats都是相对简单的单节点解决方案,针对分布式集群或者数据量级较大时会显得心有余而力不足,而ELK的出现可以使我们从容面对新的挑战。
Logstash:负责日志的收集,处理和储存
Elasticsearch:负责日志检索和分析
Kibana:负责日志的可视化
ELK(Elasticsearch + Logstash + Kibana)
更新记录 2019年07月02日 - 转载同事整理的ELK Stack进行重构
阅读原文 - https://wsgzao.github.io/post/elk/
授权转载
ELK 日志收集系统快速搭建
ELK简介 ELK 官方文档 是一个分布式、可扩展、实时的搜索与数据分析引擎。目前我在工作中只用来收集 server 的 log, 开发锅锅们 debug 的好助手。
安装设置单节点 ELK 如果你想快速的搭建单节点 ELK, 那么使用 docker 方式肯定是你的最佳选择。使用三合一的镜像,文档详情 mmap counts 大小至少 262144什么是 mmap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 sysctl -w vm.max_map_count=262144 vim /etc/sysctl.conf vm.max_map_count=262144 sysctl -p sudo yum install -y yum-utils device-mapper-persistent-data lvm2 sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo yum install -y docker-ce sudo systemctl start docker
单节点的机器,不必暴露 9200(Elasticsearch JSON interface) 和 9300(Elasticsearch transport interface) 端口。
1 2 -p 监听的IP:宿主机端口:容器内的端口 -p 192.168.10.10:9300:9300
命令行启动一个 ELK 1 2 3 4 5 sudo docker run -p 5601:5601 -p 5044:5044 \ -v /data/elk-data:/var/lib/elasticsearch \ -v /data/elk/logstash:/etc/logstash/conf.d \ -it -e TZ="Asia/Singapore" -e ES_HEAP_SIZE="20g" \ -e LS_HEAP_SIZE="10g" --name elk-ubuntu sebp/elk
将配置和数据挂载出来,即使 docker container 出现了问题。可以立即销毁再重启一个,服务受影响的时间很短。
1 2 3 4 5 6 chmod 755 /data/elk-data chmod 755 /data/elk/logstashchown -R root:root /data -v /data/elk-data:/var/lib/elasticsearch -v /data/elk/logstash:/etc/logstash/conf.d
elasticsearch 重要的参数调优
ES_HEAP_SIZE Elasticsearch will assign the entire heap specified in jvm.options via the Xms (minimum heap size) and Xmx (maximum heap size) settings. You should set these two settings to be equal to each other. Set Xmx and Xms to no more than 50% of your physical RAM.the exact threshold varies but is near 32 GB. the exact threshold varies but 26 GB is safe on most systems, but can be as large as 30 GB on some systems.
LS_HEAP_SIZE 如果 heap size 过低,会导致 CPU 利用率到达瓶颈,造成 JVM 不断的回收垃圾。 不能设置 heap size 超过物理内存。 至少留 1G 给操作系统和其他的进程。
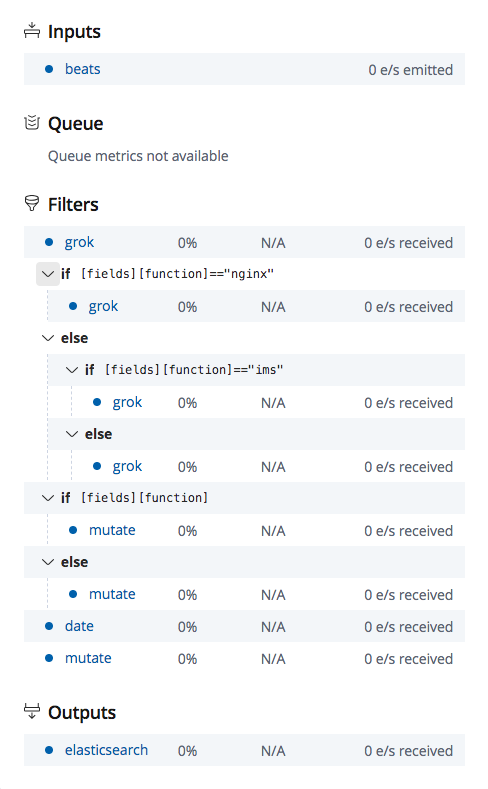
只需要配置logstash 接下来,我们再来看一看 logstash.conf 记得看注释
SSL详情可参考 grok 正则捕获 grok插件语法介绍 logstash 配置语法 grok 内置 pattern Logstash详细记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 input { beats { port => 5044 } } filter { grok { match => {"message" => "%{EXIM_DATE:timestamp}\|%{LOGLEVEL:log_level}\|%{INT:pid}\|%{GREEDYDATA}" } } if [fields][function]=="nginx" { grok { match => {"source" => "/var/log/nginx/%{GREEDYDATA:path}.log%{GREEDYDATA}" } } } else if [fields][function]=="ims" { grok { match => {"source" => "/var/log/%{GREEDYDATA:path}/%{GREEDYDATA}" } } } else { grok { match => {"source" => "/var/log/app/%{GREEDYDATA:path}/%{GREEDYDATA}" } } } if [fields][function] { mutate { add_field => { "function" => "%{[fields][function]}" } } } else { mutate { add_field => { "function" => "live" } } } date { match => ["timestamp" , "yyyy-MM-dd HH:mm:ss Z" ] target => "@timestamp" timezone => "Asia/Singapore" } mutate { gsub => ["path" ,"/" ,"-" ] add_field => {"host_ip" => "%{[fields][host]}" } remove_field => ["tags" ,"@version" ,"offset" ,"beat" ,"fields" ,"exim_year" ,"exim_month" ,"exim_day" ,"exim_time" ,"timestamp" ] } } output { elasticsearch { hosts => ["localhost:9200" ] index => "sg-%{function}-%{path}-%{+xxxx.ww}" } }
最终的流程图如下所示参考链接
Lowercase only
Cannot include , /, *, ?, “, <, >, |, ` ` (space character), ,, #
Indices prior to 7.0 could contain a colon (:), but that’s been deprecated and won’t be supported in 7.0+
Cannot start with -, _, +
Cannot be . or ..
Cannot be longer than 255 bytes (note it is bytes, so multi-byte characters will count towards the 255 limit faster)
filebeat 配置 在 client 端,我们需要安装并且配置 filebeat 请参考 Filebeat 模块与配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 filebeat.inputs: - type: log enabled: true paths: - /var/log/app/** fields: host: "{{inventory_hostname}} " function: "xxx" multiline: match: after negate: true pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}' ignore_older: 24h clean_inactive: 72h output.logstash: hosts: ["{{elk_server}} :25044" ]
批量部署 filebeat.yml 最好使用 ansible
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 --- - hosts: all become: yes gather_facts: yes tasks: - name: stop filebeat service: name: filebeat state: stopped enabled: yes - name: upload filebeat.yml template: src: filebeat.yml dest: /etc/filebeat/filebeat.yml owner: root group: root mode: 0644 - name: remove file: path: /var/lib/filebeat/registry state: absent - name: restart filebeat service: name: filebeat state: restarted enabled: yes
查看 filebeat output 首先需要修改配置,将 filebeat 输出到本地的文件,输出的格式为 json.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 filebeat.inputs: - type: log enabled: true paths: - /var/log/app/** fields: host: "x.x.x.x" region: "sg" multiline: match: after negate: true pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}' ignore_older: 24h clean_inactive: 72h output.file: path: "/home/feiyang" filename: feiyang.json
通过上述的配置,我们就可以在路径 /home/feiyang 下得到输出结果文件 feiyang.json 在这里需要注意的是,不同版本的 filebeat 输出结果的格式会有所不同,这会给 logstash 解析过滤造成一点点困难。下面举例说明 6.x 和 7.x filebeat 输出结果的不同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 { "@timestamp" : "2019-06-27T15:53:27.682Z" , "@metadata" : { "beat" : "filebeat" , "type" : "doc" , "version" : "6.4.2" } , "fields" : { "host" : "x.x.x.x" , "region" : "sg" } , "host" : { "name" : "x.x.x.x" } , "beat" : { "name" : "x.x.x.x" , "hostname" : "feiyang-localhost" , "version" : "6.4.2" } , "offset" : 1567983499 , "message" : "[2019-06-27T22:53:25.756327232][Info][@http.go.177] [48552188]request" , "source" : "/var/log/feiyang/scripts/all.log" }
6.4 与 7.2 还是有很大的差异,在结构上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 { "@timestamp" : "2019-06-27T15:41:42.991Z" , "@metadata" : { "beat" : "filebeat" , "type" : "_doc" , "version" : "7.2.0" } , "agent" : { "id" : "3a38567b-e6c3-4b5a-a420-f0dee3a3bec8" , "version" : "7.2.0" , "type" : "filebeat" , "ephemeral_id" : "b7e3c0b7-b460-4e43-a9af-6d36c25eece7" , "hostname" : "feiyang-localhost" } , "log" : { "offset" : 69132192 , "file" : { "path" : "/var/log/app/feiyang/scripts/info.log" } } , "message" : "2019-06-27 22:41:25.312|WARNING|14186|Option|data|unrecognized|fields=set([u'id'])" , "input" : { "type" : "log" } , "fields" : { "region" : "sg" , "host" : "x.x.x.x" } , "ecs" : { "version" : "1.0.0" } , "host" : { "name" : "feiyang-localhost" } }
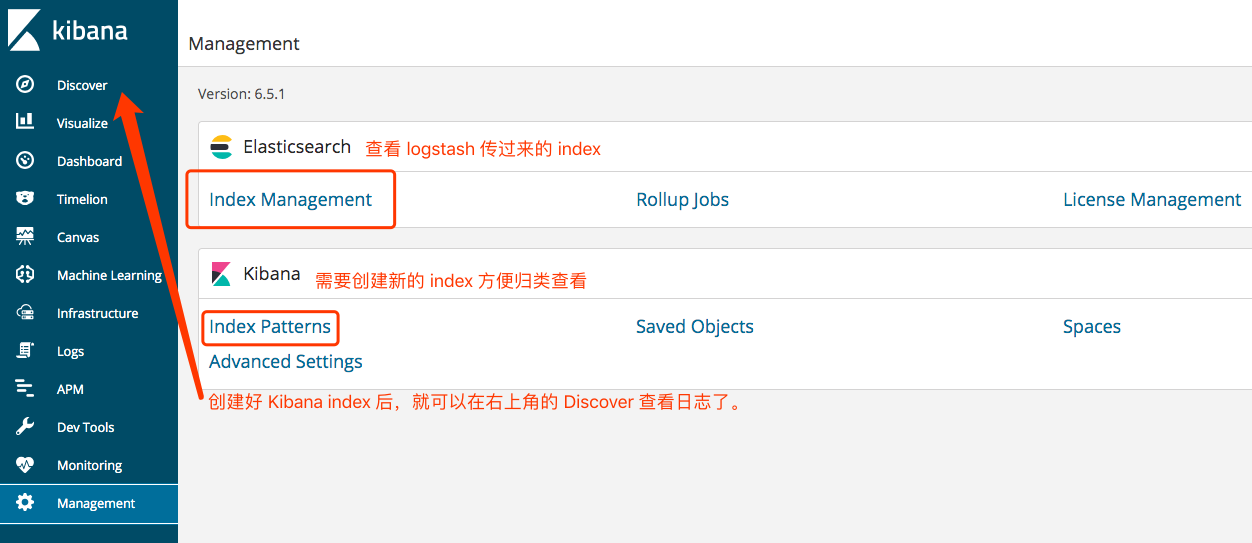
Kibana 简单的使用 在搭建 ELK 时,暴露出来的 5601 端口就是 Kibana 的服务。http://your_elk_ip:5601
安装设置集群 ELK 版本 6.7 ELK 安装文档 集群主要是高可用,多节点的 Elasticsearch 还可以扩容。本文中用的官方镜像 The base image is centos:7
Elasticsearch 多节点搭建 官方安装文档 Elasticsearch
1 2 3 4 5 6 7 mkdir -p /data/elk-data && chmod 755 /data/elk-datachown -R root:root /data docker run -p WAN_IP:9200:9200 -p 10.66.236.116:9300:9300 \ -v /data/elk-data:/usr/share/elasticsearch/data \ --name feiy_elk \ docker.elastic.co/elasticsearch/elasticsearch:6.7.0
接下来是修改配置文件 elasticsearch.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cluster.name: "feiy_elk" network.host: 0.0 .0 .0 node.master: true node.data: true node.name: node-1 network.publish_host: 10.66 .236 .116 discovery.zen.ping.unicast.hosts: ["10.66.236.116:9300" ,"10.66.236.118:9300" ,"10.66.236.115:9300" ]
1 2 3 4 5 6 7 8 9 10 11 12 cluster.name: "feiy_elk" network.host: "0.0.0.0" node.name: node-2 node.data: true network.publish_host: 10.66 .236 .118 discovery.zen.ping.unicast.hosts: ["10.66.236.116:9300" ,"10.66.236.118:9300" ,"10.66.236.115:9300" ]
1 2 3 4 5 6 7 8 9 10 11 12 cluster.name: "feiy_elk" network.host: "0.0.0.0" node.name: node-3 node.data: true network.publish_host: 10.66 .236 .115 discovery.zen.ping.unicast.hosts: ["10.66.236.116:9300" ,"10.66.236.118:9300" ,"10.66.236.115:9300" ]
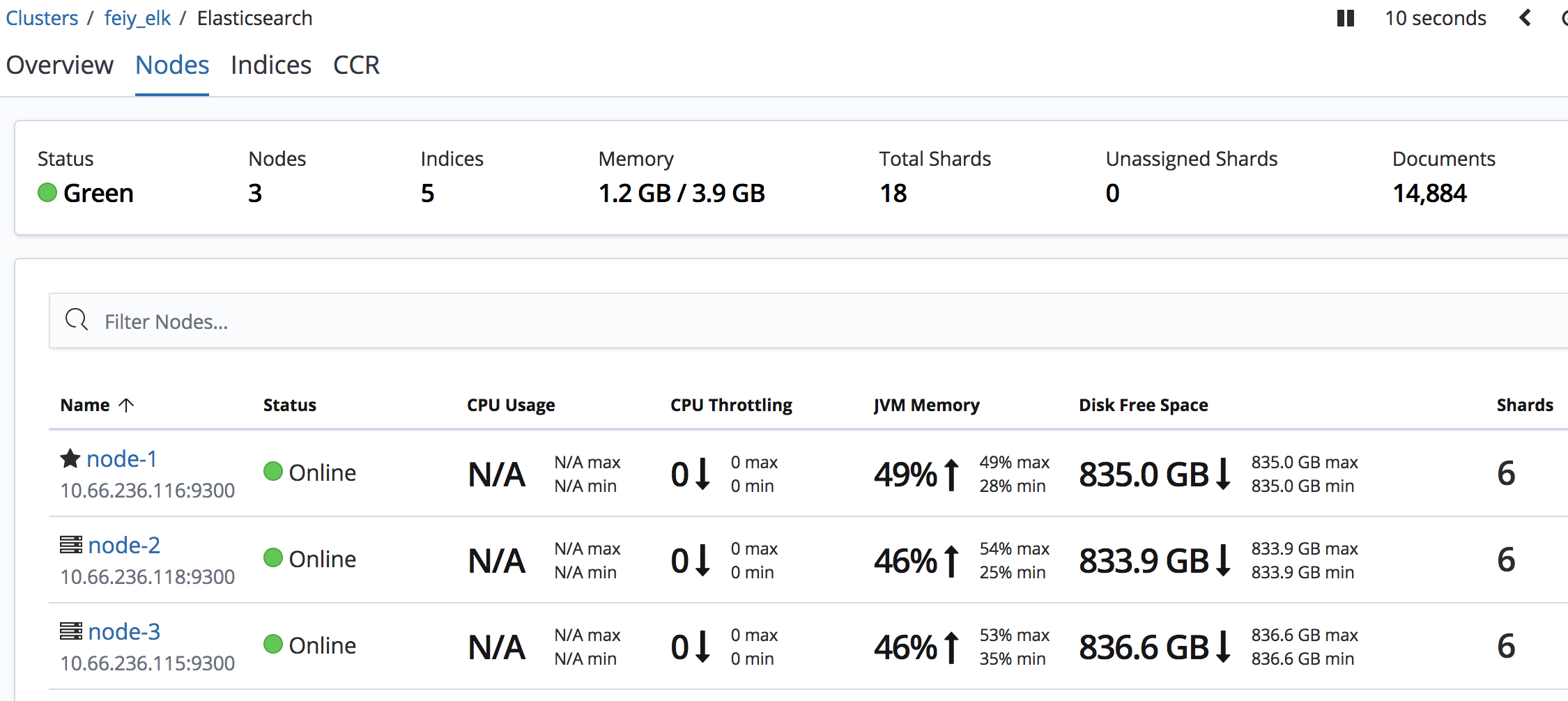
检查集群节点个数,状态等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 { "cluster_name" : "feiy_elk" , "status" : "green" , "timed_out" : false , "number_of_nodes" : 3, "number_of_data_nodes" : 3, "active_primary_shards" : 9, "active_shards" : 18, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
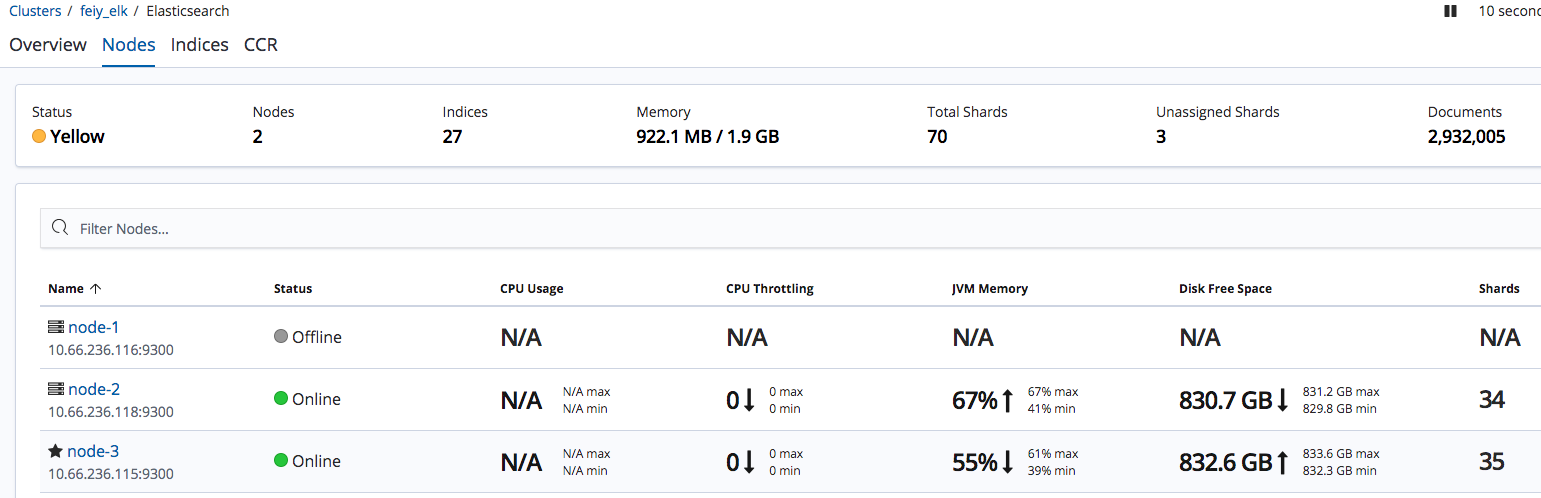
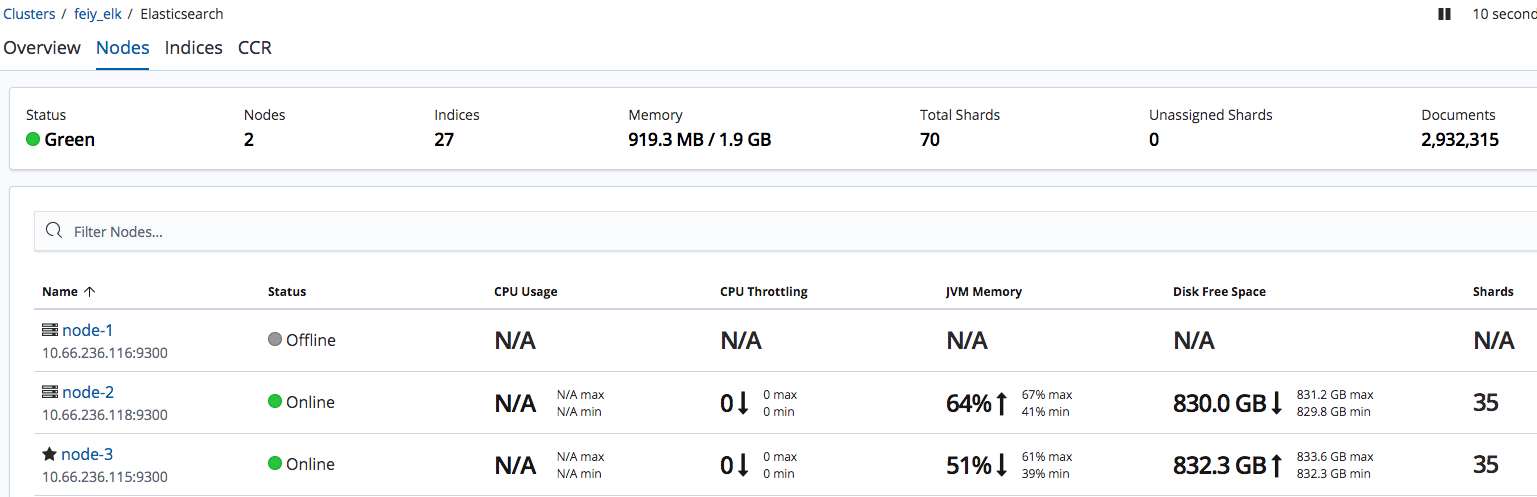
最终结果图在 kibana 上可以看到集群状态
Kibana 搭建 官方安装文档 Kibana
1 2 3 4 5 6 docker run -p 外网IP:5601:5601 --link elasticsearch容器的ID:elasticsearch docker.elastic.co/kibana/kibana:6.7.0 docker run -p 外网IP:5601:5601 docker.elastic.co/kibana/kibana:6.7.0
we recommend that you use user-defined networks to facilitate communication between two containers instead of using –link
1 2 3 4 5 6 7 8 9 10 11 server.name: kibana server.host: "0.0.0.0" elasticsearch.hosts: [ "http://172.17.0.2:9200" ]xpack.monitoring.ui.container.elasticsearch.enabled: true docker restart [container_ID ]
Logstash 搭建 官方安装文档 Logstash
1 2 3 4 docker run -p 5044:5044 -d --name test_logstash docker.elastic.co/logstash/logstash:6.7.0 docker run -p 192.168.1.2:5044:5044 -d --name test_logstash docker.elastic.co/logstash/logstash:6.7.0
1 2 3 4 hosts => ["IP Address 1:port1" , "IP Address 2:port2" , "IP Address 3" ]
logstash 过滤规则 见上文的配置和 grok 语法规则
1 2 3 4 5 6 http.host: "0.0.0.0" xpack.monitoring.elasticsearch.url: http://elasticsearch_master_IP:9200 node.name: "feiy" pipeline.workers: 24
改完配置 exit 从容器里退出到宿主机,然后重启这个容器。更多配置详情,参见官方文档
1 2 3 4 docker ps -a docker restart [container_ID]
容灾测试 我们把当前的 master 节点 node-1 关机,通过 kibana 看看集群的状态是怎样变化的。官方文档 ,再过一会发现集群状态变成了绿色。
kibana 控制台 Console Quick intro to the UI
Console understands requests in a compact format, similar to cURL:
1 2 3 4 5 6 7 8 PUT index/type/1 { "body" : "here" } GET index/type/1
While typing a request, Console will make suggestions which you can then accept by hitting Enter/Tab. These suggestions are made based on the request structure as well as your indices and types.
A few quick tips, while I have your attention
Submit requests to ES using the green triangle button.
Use the wrench menu for other useful things.
You can paste requests in cURL format and they will be translated to the Console syntax.
You can resize the editor and output panes by dragging the separator between them.
Study the keyboard shortcuts under the Help button. Good stuff in there!
Console 常用的命令 Kibana 控制台 ELK技术栈中的那些查询语法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 GET _search { "query": { "match_all": {} } } GET /_cat/health?v GET /_cat/nodes?v GET /_cluster/allocation/explain GET /_cluster/state GET /_cat/thread_pool?v GET /_cat/indices?health=red&v GET /_cat/indices?v #将当前所有的 index 的 replicas 设置为 0 PUT /*/_settings { "index" : { "number_of_replicas" : 0, "refresh_interval": "30s" } } GET /_template # 在单节点的时候,不需要备份,所以将 replicas 设置为 0 PUT _template/app-logstash { "index_patterns": ["app-*"], "settings": { "number_of_shards": 3, "number_of_replicas": 0, "refresh_interval": "30s" } }
Elasticsearch 数据迁移 Elasticsearch 数据迁移官方文档 感觉不是很详细。容器化的数据迁移,我太菜用 reindex 失败了,snapshot 也凉凉。An Elasticsearch Migration Tool 进行数据迁移的。
1 2 3 4 wget https://github.com/medcl/esm-abandoned/releases/download/v0.4.2/linux64.tar.gz tar -xzvf linux64.tar.gz ./esm -s http://127.0.0.1:9200 -d http://192.168.21.55:9200 -x index_name -w=5 -b=10 -c 10000 --copy_settings --copy_mappings --force --refresh
Nginx 代理转发 因为有时候 docker 重启,iptables restart 也会刷新,所以导致了我们的限制规则会被更改,出现安全问题。这是由于 docker 的网络隔离基于 iptable 实现造成的问题。为了避免这个安全问题,我们可以在启动 docker 时,就只监听在内网,或者本地 127.0.0.1 然后通过 nginx 转发。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # cat kibana.conf server { listen 25601; server_name x.x.x.x; access_log /var/log/nginx/kibana.access.log; error_log /var/log/nginx/kibana.error.log; location / { allow x.x.x.x; allow x.x.x.x; deny all; proxy_http_version 1.1; proxy_buffer_size 64k; proxy_buffers 32 32k; proxy_busy_buffers_size 128k; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_pass http://127.0.0.1:5601; } }
! 这里需要注意的是, iptable filter 表 INPUT 链 有没有阻挡 172.17.0.0/16 docker 默认的网段。是否阻挡了 25601 这个端口。
踩过的坑
iptables 防不住。需要看上一篇博客 里的 iptable 问题。或者监听在内网,用 Nginx 代理转发。
elk 网络问题
elk node
discovery.type=single-node 在测试单点时可用,搭建集群时不能设置这个环境变量,详情见官方文档 ELK的一次吞吐量优化
filebeat 版本过低导致 recursive glob patterns ** 不可用1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 --- - hosts: all become: yes gather_facts: yes tasks: - name: upload filebeat.repo copy: src: elasticsearch.repo dest: /etc/yum.repos.d/elasticsearch.repo owner: root group: root mode: 0644 - name: install the latest version of filebeat yum: name: filebeat state: latest - name: restart filebeat service: name: filebeat state: restarted enabled: yes [elasticsearch-6.x ] name=Elasticsearch repository for 6. x packages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
filebeat 7.x 与 6.x 不兼容问题. 关键字变化很大, 比如说 “sorce” 变为了 [log][file][path]
参考文章
腾讯云Elasticsearch Service 这个腾讯云的专栏非常的不错,请您一定要点开看一眼,总有你想要的。 ELK重难点总结和整体优化配置